Глава 3. Обработка экспериментальных данных
Работа с файлами данных формата JDX
Рассмотрим возможность обрабатывать информацию, которая хранится в файлах формата JCAMP-DX. Это широко распространённый формат для хранения спектроскопических данных, поддерживаемый The joint Committee on Atomic and Molecular Physical data. Их обычно создаёт и обрабатывает программное обеспечение для ИК или Рамановского спектрометра, но программы для многих других типов автоматизированных спектроскопических приборов также могут работать с этим форматом.
Файлы подобного типа имеют расширение .jdx
Файл jdx текстовый формат, однако его структура крайне сложна. Достаточно сказать, что значения экспериментальных точек по оси абсцисс указаны с другим шагом, нежели значения этих же точек по оси ординат. Для того, чтобы прочитать, например, ИК-спектр из файла, обычно приходится писать собственный алгоритм, пользуясь открытым описанием формата. Для языка Python ситуация проще, так как для работы с этим форматом уже написан соответствующий модуль jcamp, который имеет смысл научиться применять. Установка модуля:
pip install jcamp
В нашем случае файл test.JDX содержит реальный спектр инфракрасного поглощения. Прочитаем данные и отобразим их на графике с помощью следующей программы:
Просмотр структуры словаря с использованием iPython:
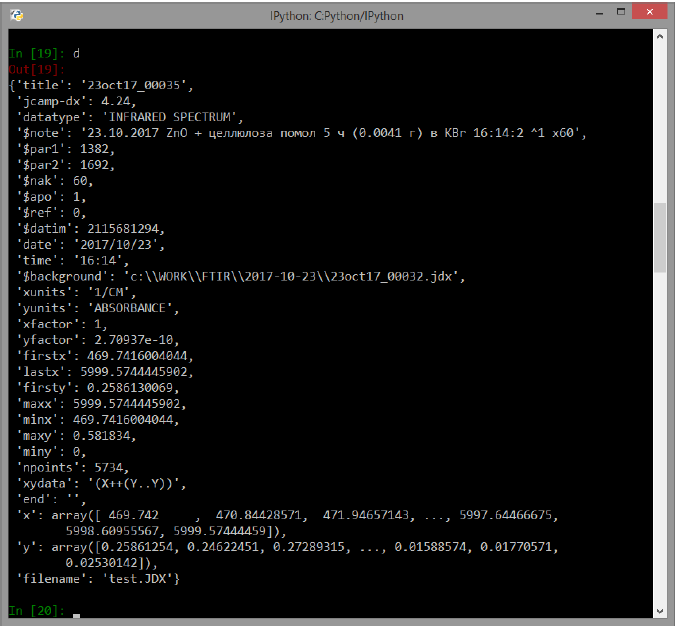
Как следует из вида словаря, для отображения графика нам достаточно взять элементы ‘x’ и ‘y’, что и сделано в строке 5 листинга. Поскольку обозначения осей координат тоже взяты из файла и находятся в словаре, используем их в строках 9 и 10 для отображения на графике. И, поскольку при публикации ИК-спектров ось абсцисс часто изображают в направлении от максимальных волновых чисел к минимальным, инвертируем ось с помощью метода gca().invert_xaxis() библиотеки matplotlib (строка 5). Если команды листинга выполнять интерактивно с помощью iPython, команда в строке 12 не нужна.
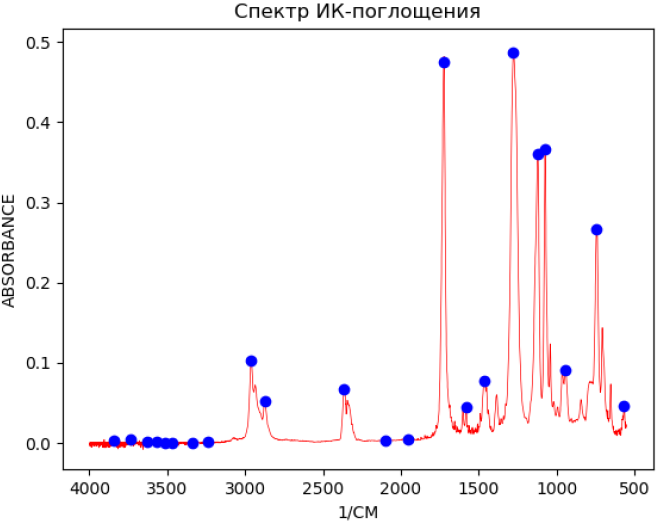
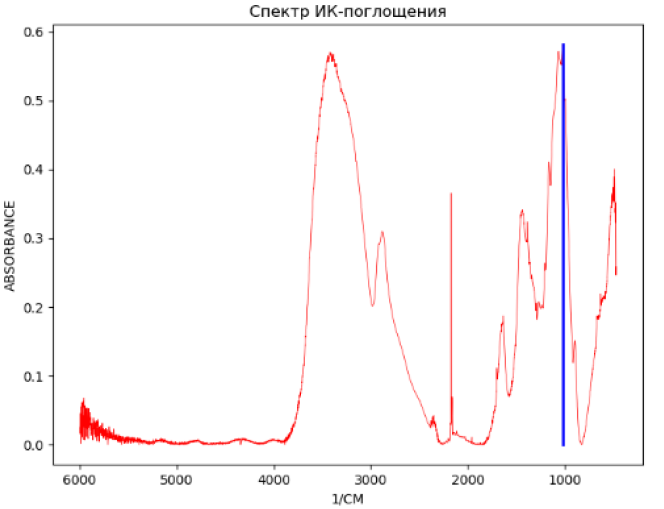
На рисунке выше синяя линия показывает позицию абсолютного максимума на кривой. Попробуем, используя iPython, осуществить поиск и индикацию этого максимума следующим образом:
Конечно, подобным образом мы можем найти только самый большой пик или, например, выброс в экспериментальных значениях. Но если нам необходимо узнать позиции всех пиков, то требуется либо написать собственный алгоритм, основываясь на априорной информации о том, что следует считать достоверным пиком поглощения, либо попытаться адаптировать уже готовые алгоритмы, которые также можно найти в библиотеке scipy. Например, метод find_peaks_cwt осуществляет поиск пиков в одномерном массиве Y, указанном в качестве первого параметра. Второй параметр – это список возможных ширин пиков. В нашем случае ширина «пика» выбрана большей 10 точек, но меньшей 100. Результат, показанный ниже уже может удовлетворить экспериментатора, при этом следует иметь в виду, что возможна настройка и других параметров указанного метода.
Под шириной пика понимается количество подряд идущих значений в массиве Y, которые вместе могут составлять некий пик.