Глава 2. Получение и визуализация данных эксперимента
Загрузка данных из файла и их визуализация
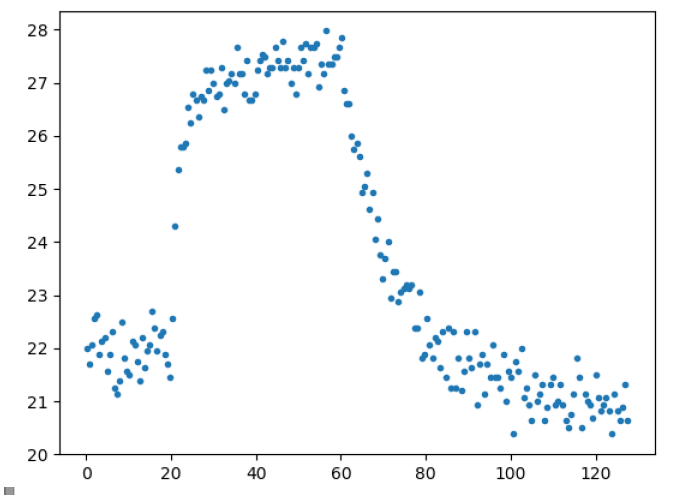
Итак, мы собрали данные с термопары и записали их в файл alpha.txt. Чтение файла и визуализация данных не представляет проблемы, но способ обработки списков имеет свои особенности.
Первый вариант программы:
Для упрощения работы с файлом здесь использована конструкция with, которая корректно отрабатывает открытие и закрытие файла.
Для того чтобы корректно отобразить данные на графике, нам нужно взять второй и третий столбцы списка. Не используя библиотеку numpy, вырезать столбец из data можно так, как показано в строках 11 и 12, для этого потребовалось создать дополнительные списки X и Y.
Второй вариант программы с использованием библиотеки numpy :
Как видим, программа существенно упростилась, однако следует обратить внимание на строку 4: импорт данных с помощью метода genfromtxt осуществляется в структурированный массив с именованными столбцами, при этом имена столбцов и тип данных указывается в списке значений параметра dtype. В случае, если тип не указан, он будет определяться по введённым значениям. Результат записывается в массив data, но структура этого массива отличается от списка предыдущей программы. В этой связи, для вывода графика в методе plot достаточно указать имя столбца в массиве data для выбора необходимых срезов матрицы (строка 7).
Третий вариант программы с использованием библиотеки pandas:
Библиотека pandas предполагает использовать специальные алгоритмы обработки и анализа больших данных.